
By: Jeff Kosovich and Elizabeth Brondos Fry
We see things that we interpret every day:
- The mail truck driving down a residential road is probably going to deliver the mail.
- To a millennial, an all-caps email might mean the sender is shouting.
- The person you are talking to is not making eye contact, so they must be ignoring you.
- The car in the lane next to you doesn’t make space for you to merge—that jerk.
Each of these examples represent a measurement, some data, and a conclusion.

Each person who reads the measurements and data in the table above may or may not agree with the conclusions provided. Most readers will probably agree that the mail truck example is probably true. However, it is not so obvious that the all-caps email conveys shouting. Maybe it simply conveys excitement. Maybe it is just how the sender types. Is the person who is not making eye contact with you disengaged in what you are saying, or did they grow up in a culture where eye contact during conversation is considered rude? Finally, is the other driver a jerk for not letting you merge, or did you forget to turn on your signal, meaning they had no knowledge that you planned to merge?
Whether or not the conclusions are merited is the core of the concept of Validity. We often talk about measurement as a complicated process that happens using surveys, interviews, or analyzing big data, but the truth is that measurement happens every day in many ways. And after most of those daily measurements, we draw conclusions about what we see, feel, hear, or think.
“I know it’s not a validated measure, but I think it provides useful information”
We cannot tell you how many times we have heard that phrase in our careers and it makes us cringe every time. You cannot assume that an assessment will work in every context any more than you can assume that the aforementioned mail truck can meet all of your transportation needs. The fact that the truck has been cleared to drive on residential roads has no bearing on how well it will drive in a swamp, a sand dune, or the sky.

Similarly, while the truck might be good for transporting mail and packages, it is not necessarily the best option for transporting a refrigerator. You might be able to fit a few select appliances in a mail truck, but they are probably best delivered in a truck designed for larger cargo.
So, why do people think their measure will work in one setting, and then assume that it can work just as well in totally different settings? People do not tend to assume a mail truck can fly after watching it drive down the road. The concept of “validated measures,” as a black-and-white, “yes” or “no” box to be checked, is outdated in psychological measurement theory.i For many years, the prevailing wisdom was that you design an assessment and then you check a few key things:
- If the assessment is related to other measures of the same attribute
- If the questions represent the idea being measured
- If scores on the measure correspond with important outcomes.
If all the boxes were checked, the measure was validated and ready to use. The problem with the validated measures perspective is that it assumes validity is a static characteristic of the measure; it has little to no consideration for changing or unanticipated contexts. While each of the validation tests listed above may represent sources of validity evidence, they are not always relevant for all measures.
For example, consider the two following math problems.
 The example on the left only requires knowledge of how the numbers interact. The example on the right requires the user to be able to read English, to understand what “a dozen” means, and needs to understand what “have left” means. If your math teacher is feeling particularly vindictive, it also makes the implicit assumption that nobody else is eating Cindy’s chocolates. In fact, educational research suggests that reading comprehension is a major factor for math problem solving in school-aged childrenii as well as adults who are not native speakers.iii
The example on the left only requires knowledge of how the numbers interact. The example on the right requires the user to be able to read English, to understand what “a dozen” means, and needs to understand what “have left” means. If your math teacher is feeling particularly vindictive, it also makes the implicit assumption that nobody else is eating Cindy’s chocolates. In fact, educational research suggests that reading comprehension is a major factor for math problem solving in school-aged childrenii as well as adults who are not native speakers.iii
Rather than state that a measure is validated, we need to ask if there is sufficient evidence to justify our conclusions. If a child cannot solve a word problem, are they bad at math, or do they just need additional development in reading?
In some instances, a lack of validity might be okay as is the case in completing a “What kind of pizza are you?” quiz
In other instances, a lack of validity might lead to very real consequences:
- A child is forced to repeat a math class rather than receive supplemental language classes.
- A brilliant candidate is passed over because they are not a native speaker of the dominant language at the organization.
- A teacher treats students differently based on a label generated from unsupported research.iv
Based on this, you might see why the phrase “I know it’s not a validated measure, but I think it provides useful information” is problematic. If you ignore whether there is appropriate evidence to use a particular measure, you are essentially saying “People may interpret this question very differently, and it might not even measure what I’m talking about, but let’s pretend it does.” Imagine a team lead claiming their project was a wild financial success without a single receipt, billing statement, or contract to corroborate the results.
“Fine, Validity is Important—But Creating Measures is Pretty Intuitive, Right?”
While it may seem easy to just throw some questions together that you feel good about and call it a measure, there is nuance involved in developing assessments. To be honest, validating even a simple measure can be annoyingly tedious.
Consider the following examples and the effect they might have on which conclusions they support:
Example 1: If you want to know what people think, just ask them
One example of how minor wording changes can affect validity comes from a survey early in Jeff’s research career. We were studying the value that students associate with math and asked students to rate the extent to which “Math is important.”
The question was met with very high ratings. On average the question was rated a 4.5 from a five-point scale. None of the other 30 questions we asked had even remotely similar ratings—even similarly worded questions.
The inconsistency led us to explore the results further and we eventually changed the wording to “Math is important to me.” The average score drastically decreased below an average of 3. Essentially, everyone thinks that math is important, but few people feel that is directly important to them.
This example demonstrates an important component of validity evidence: reliability. If we ask a series of questions about the same topic, we expect to hear consistent information. If one of those questions leads to unrelated information, it is possible that that the question does not belong with the others.
Similarly, think about asking friends or colleagues for input. Is it easier to decide if all three people agree on the next step, or if all three people suggest different opposing actions? How do you decide?
Example 2: What else could “technology utilization” possibly mean?
Another example comes from a survey of introductory statistics instructors that Elizabeth helped to revise as a graduate research assistant. We wanted to know how well instructors were following statistics education recommendationsv regarding technology use. In the courses taught by the survey designers, “using technology” in the classroom meant having students use software or online applets to complete guided activities.
However, cognitive interviews to gather validity evidence revealed that some instructors interpreted technology use as demonstrating tools in lecture rather than having students interact with them. The question was not interpreted the same way in a different context than where it was created. To receive more accurate ratings, the survey questions needed to specifically ask about students using the technology.
Example 3: This survey takes two-thirds of the time; it is obviously superior
Another consideration is that survey formatting can directly change how people respond to questions. Despite identical phrasing in a recent survey we were testing, questions formatted for more compact display tended to receive higher, less-diverse ratings in 1/3 less time when compared to lengthier formats. Let us be clear, low time investment is often a positive property of an assessment, but we need to weigh the cost of cutting time.
In the survey described, 13 of the 17 questions in the compact format had a higher average score than items in the lengthier format. On average, the compact-format scores were 0.13 points higher, and the largest difference was 0.32 points. Of the 17 questions, 5 displayed statistically significant gaps between the two formats.
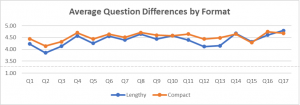
While the differences seem to be small, they can still lead to different conclusions, particularly when people are overly strict about cut-off values. Some clients may react very differently to a 4.15 satisfaction rating than a 3.85 because of their own personal conclusions and standards.
So What?
Validity studies are a lot of work but are also highly valuable. Even testing the measure with a pilot group and asking participants to think through your questions out loud can be helpful. Realistically though, a strong validation study can take months or even years.
For example, CCL’s 360 Feedback Assessments comprise dozens of measures with decades of validation, and we are still in the process of updating and refining them to address new needs, contexts, and considerations.
If you are trying to measure something, it is critically important to think about how you will use those measures. Understanding the quality of a measure is more than just making sure a few boxes are checked off the validity list—you need to think about the evidence supporting its use.
More importantly, as we suggested in our math problem example, it is important to consider how measures with little-to-no validity evidence are often used in ways that could shape opportunities, experiences, or even treatments for people when the data are applied to policies, procedures, or decision-making. Over time or at scale, poorly validated measures could result in inequitable experiences across a variety of settings.
Instead of trying to “validate” a measure, think about how you will support your conclusions with sources of validity evidence. As you consider the next time you plan to create or use a measure, remember the following questions:
- What conclusions do you hope to draw?
- What evidence exists to support those specific conclusions?
- Are you using the measure in a new way or with new people?
- What are the consequences of inaccurate results?
- In the face of insufficient evidence, how might you temper your conclusions?
Okay. Maybe it is not quite lying if you do not know you are wrong. But you might want to check.
References
i American Educational Research Association, American Psychological Association, & National Council on Measurement in Education (Eds.). (2014). Standards for educational and psychological testing. American Educational Research Association.
ii Öztürk, M., Yaşar A., & Kaplan, A. (2020). Reading comprehension, Mathematics self-efficacy perception, and Mathematics attitude as correlates of students’ non-routine Mathematics problem-solving skills in Turkey, International Journal of Mathematical Education in Science and Technology, 51(7), 1042-1058. https://doi.org/10.1080/0020739X.2019.1648893″>https://doi.org/10.1080/0020739X.2019.1648893
iii Cruz Neri, N., Wagner, J. & Retelsdorf. J. (2021). What makes mathematics difficult for adults? The role of reading components in solving mathematics items, Educational Psychology, 41(9), 1199-1219. https://doi.org/10.1080/01443410.2021.1964438
iv Pashler, H., McDaniel, M., Rohrer, D., & Bjork, R. (2008). Learning Styles: Concepts and Evidence. Psychological Science in the Public Interest, 9(3), 105–119. https://doi.org/10.1111/j.1539-6053.2009.01038.x
v GAISE College Report ASA Revision Committee, “Guidelines for Assessment and Instruction in Statistics Education College Report 2016,” https://www.amstat.org/docs/default-source/amstat-documents/gaisecollege_full.pdf
